1+ ---
2+ title : " Gemma-2 + RAG + LlamaIndex + VectorDB"
3+ date : 2024-07-14T00:00:00+01:00
4+ description : Open Source LLM + Local RAG
5+ menu :
6+ sidebar :
7+ name : Gemma-2 + RAG
8+ identifier : gemma2_rag
9+ parent : nlp
10+ weight : 9
11+ hero : mermaid-diagram.svg
12+ tags : ["Deep Learning", "NLP", "Machine Learning"]
13+ categories : ["NLP"]
14+ ---
115
216
3- # Gemma-2 + RAG + LlamaIndex + VectorDB
417
518
619
7- ## Introduction
20+ ## 1. Introduction
821Retrieval-Augmented Generation (RAG) is an advanced AI technique that enhances large language models (LLMs) with the ability to access and utilize external knowledge. This guide will walk you through a practical implementation of RAG using Python and various libraries, explaining each component in detail.
922
1023[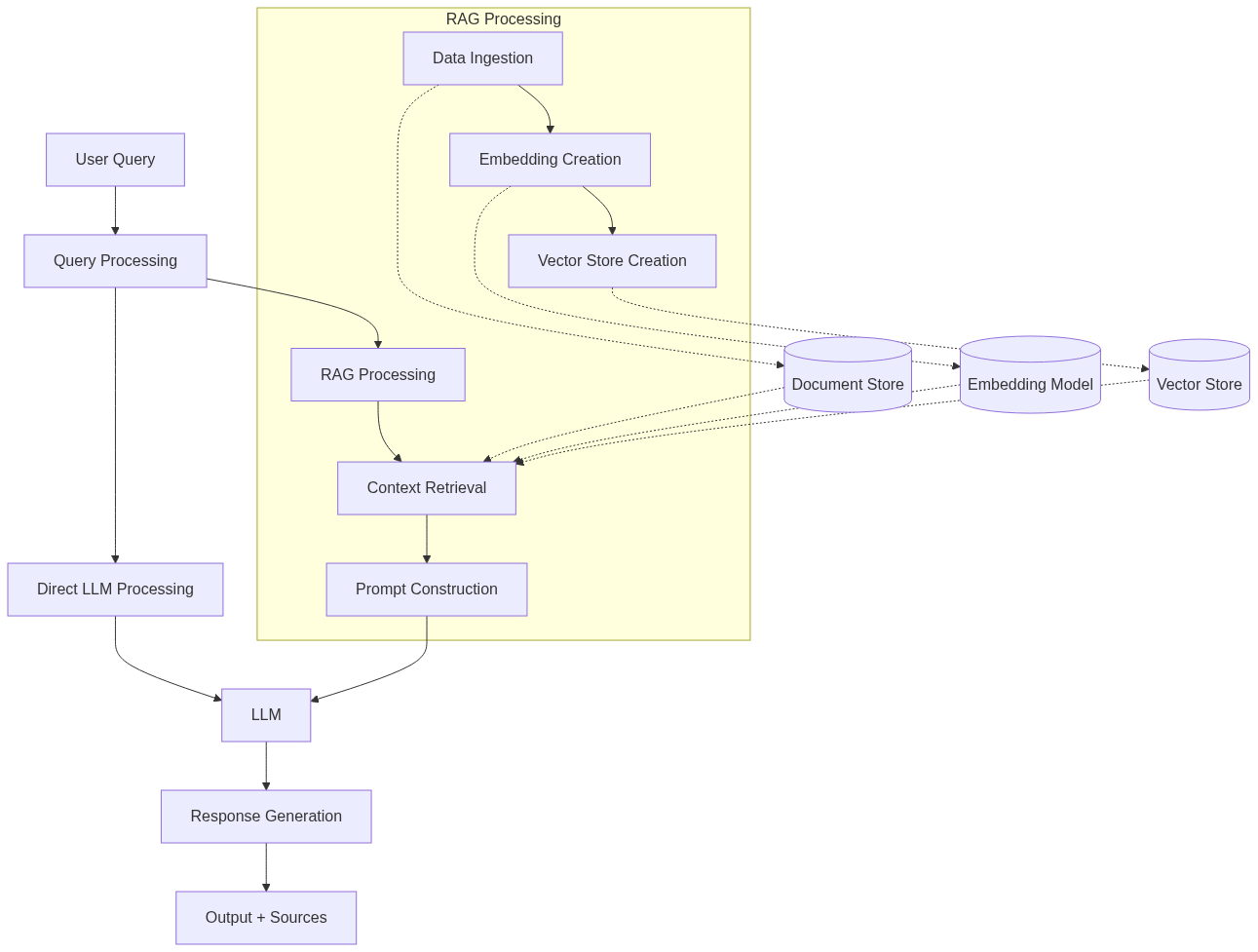](https://mermaid.live/edit#pako:eNp1kt9ugjAUxl-l6ZXLdA_AxRIF_0VQp9tuiheVHpEEWlLaZcb47ju2uOGWcXHC6fdr-fpxzjRTAmhAc83rI3mNUknwGbK3BjR5saBPOzIYPJMRcw1Za5VB0xQy33l05OSQRYWGzJA4Tv5jIrYZTv-KvjZ27y2k9J5KqQfGLOKGk7nMoTGFkt7WhI2rPQiBIAk1cKf4DRMHTNk72lKabLHAbyZyzIyFShr4NGQDRhfwwctWnzl9ztBOVRuCWGO0zTongBTda_gaum0LhmG02NyvdKGFW4rZBpoazwUyBQm66y52RMJW1tTWkEeyVVZjLHfBjcngCakl60UqsxVI46_60FJLr8--Q7l2K9b7yS3BCShv-OoOn_puzXrdFG_sumVpn1agK14IHKTzVUupOUIFKQ3wVcCB29Jcf-QFUW6N2p5kRgOMEvpUK5sfaXDgZYOdrQU3EBUcp6G6ISAK_G7iJzVT8lDk9PIFuI7TUA)
1124
12- ## Setup and Import
25+ ## 2. Setup and Import
1326
1427
1528``` python
@@ -50,7 +63,7 @@ login(token=secret_value)
5063
5164
5265
53- ## Model and VectorDB imports
66+ ## 3. Model and VectorDB imports
5467* This section imports various components from ** llama_index** for document processing, indexing, and querying.
5568* It sets up ** FAISS** (Facebook AI Similarity Search) for efficient similarity search in high-dimensional spaces.
5669
@@ -144,7 +157,7 @@ embed_model = HuggingFaceEmbedding(model_name="sentence-transformers/all-MiniLM-
144157 1_Pooling/config.json: 0%| | 0.00/190 [00:00<?, ?B/s]
145158
146159
147- ## Language Model Setup and Loading
160+ ## 4. Language Model Setup and Loading
148161* It uses the "google/gemma-2-9b-it" model, a powerful instruction-tuned language model.
149162* It configures 8-bit quantization to reduce memory usage
150163* The tokenizer is set globally for consistency.
@@ -168,52 +181,6 @@ llm_model = HuggingFaceLLM(model_name="google/gemma-2-9b-it",
168181```
169182
170183
171- tokenizer_config.json: 0%| | 0.00/40.6k [00:00<?, ?B/s]
172-
173-
174-
175- tokenizer.model: 0%| | 0.00/4.24M [00:00<?, ?B/s]
176-
177-
178-
179- tokenizer.json: 0%| | 0.00/17.5M [00:00<?, ?B/s]
180-
181-
182-
183- special_tokens_map.json: 0%| | 0.00/636 [00:00<?, ?B/s]
184-
185-
186-
187- config.json: 0%| | 0.00/857 [00:00<?, ?B/s]
188-
189-
190-
191- model.safetensors.index.json: 0%| | 0.00/39.1k [00:00<?, ?B/s]
192-
193-
194-
195- Downloading shards: 0%| | 0/4 [00:00<?, ?it/s]
196-
197-
198-
199- model-00001-of-00004.safetensors: 0%| | 0.00/4.90G [00:00<?, ?B/s]
200-
201-
202-
203- model-00002-of-00004.safetensors: 0%| | 0.00/4.95G [00:00<?, ?B/s]
204-
205-
206-
207- model-00004-of-00004.safetensors: 0%| | 0.00/3.67G [00:00<?, ?B/s]
208-
209-
210-
211- Loading checkpoint shards: 0%| | 0/4 [00:00<?, ?it/s]
212-
213-
214-
215- generation_config.json: 0%| | 0.00/173 [00:00<?, ?B/s]
216-
217184
218185## Direct LLM Querying
219186This part demonstrates direct querying of the LLM:
0 commit comments