You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Copy file name to clipboardExpand all lines: _posts/2025-04-04-mixtral-of-experts.md
+10-12Lines changed: 10 additions & 12 deletions
Display the source diff
Display the rich diff
Original file line number
Diff line number
Diff line change
@@ -61,7 +61,7 @@ Mixtral 8x7B와 Mixtral 8x7B – Instruct 모델은 모두 Apache 2.0 라이선
61
61
62
62
## 아키텍처 세부 사항
63
63
64
-
Mixtral은 트랜스포머 아키텍처를 기반으로 하며, [Vaswani와 연구진](https://arxiv.org/pdf/1706.03762v7)이 제안한 원래의 트랜스포머 모델에 [Jiang과 연구진](https://arxiv.org/pdf/2310.06825)이 설명한 수정사항을 적용하고 있습니다. 그러나 Mixtral은 두 가지 주요한 차이점을 가지고 있습니다. 첫째, 32k 토큰의 완전 밀집 컨텍스트 길이를 지원하며, 둘째, 피드포워드 블록이 전문가 혼합(Mixture-of-Expert) 층으로 대체되었습니다. 모델 아키텍처의 주요 매개변수는 아래 표에 요약되어 있습니다.
64
+
Mixtral은 트랜스포머 아키텍처를 기반으로 하며, [Vaswani와 연구진](https://arxiv.org/pdf/1706.03762v7)이 제안한 원래의 트랜스포머 모델에 [Jiang과 연구진](https://arxiv.org/pdf/2310.06825)의 개선사항을 적용하고 있습니다. 그러나 Mixtral은 두 가지 주요한 차이점을 가지고 있습니다. 첫째, 32k 토큰의 완전 밀집 컨텍스트 길이를 지원하며, 둘째, 피드포워드 블록이 전문가 혼합(Mixture-of-Expert) 층으로 대체되었습니다. 모델 아키텍처의 주요 매개변수는 아래 표에 요약되어 있습니다.
65
65
66
66
| 매개변수 | 값 |
67
67
|---------|-----|
@@ -124,7 +124,7 @@ Mixtral 모델을 Llama와 비교하기 위해 다양한 벤치마크에서 자
124
124
125
125
126
126
127
-
위 표는 Mixtral과 Llama 모델 간의 상세한 성능 비교를 보여줍니다. Mixtral 8x7B는 추론 과정에서 5배 적은 활성 매개변수를 사용하면서도 거의 모든 인기 벤치마크에서 Llama 2 70B의 성능을 능가하거나 일치시킵니다.
127
+
아래 표는 Mixtral과 Llama 모델 간의 상세한 성능 비교를 보여줍니다. Mixtral 8x7B는 추론 과정에서 5배 적은 활성 매개변수를 사용하면서도 거의 모든 인기 벤치마크에서 Llama 2 70B의 성능을 능가하거나 일치시킵니다.
- 인기 종합 결과: MMLU([Hendrycks와 연구진](https://arxiv.org/abs/2009.03300))(5-shot), BBH([Suzgun와 연구진](https://arxiv.org/abs/2210.09261))(3-shot), AGI Eval([Zhong와 연구진](https://arxiv.org/abs/2304.06364))(3-5-shot, 영어 객관식 문제만)
146
146
147
-
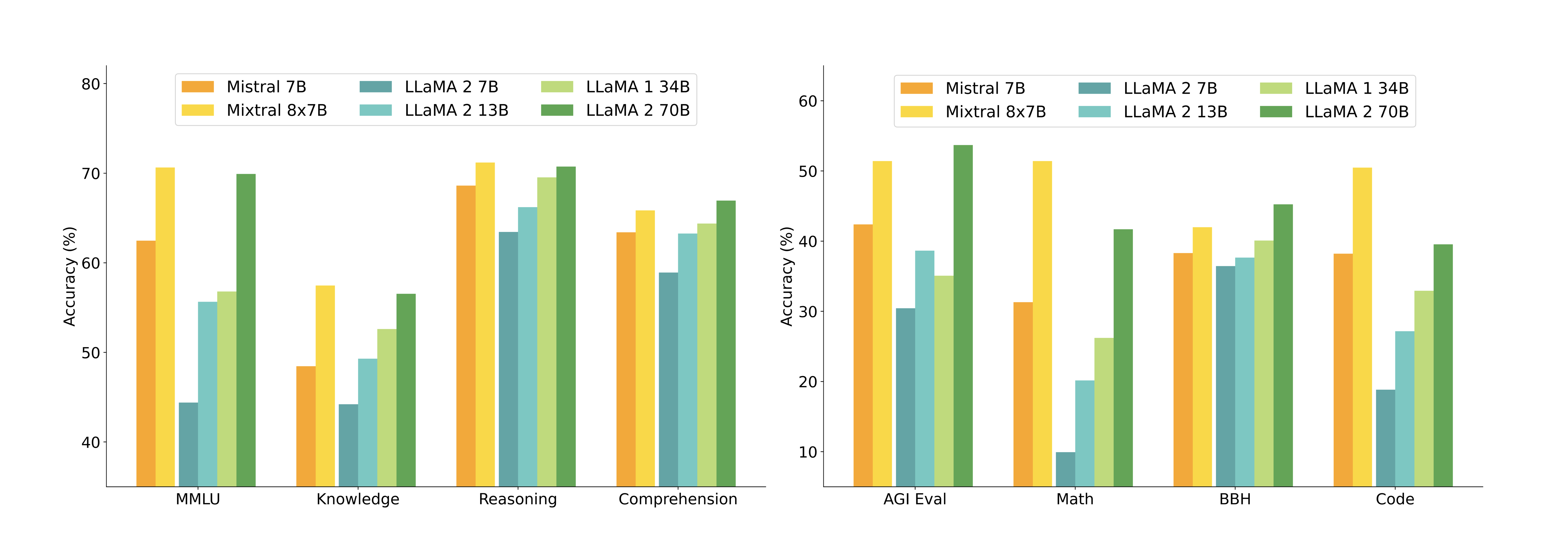
아래 그림는 다양한 카테고리에서 Mixtral과 Llama 모델들의 성능을 비교합니다. Mixtral은 대부분의 지표에서 Llama 2 70B를 능가합니다. 특히 코드와 수학 벤치마크에서 우수한 성능을 보여줍니다.
147
+
아래 그림은 다양한 카테고리에서 Mixtral과 Llama 모델들의 성능을 비교합니다. Mixtral은 대부분의 지표에서 Llama 2 70B를 능가합니다. 특히 코드와 수학 벤치마크에서 우수한 성능을 보여줍니다.
148
148
149
149

150
150
@@ -158,7 +158,7 @@ Mixtral 모델의 성능을 Llama 2 계열과 비교하여 비용-성능 스펙
158
158
159
159
### Llama 2 70B 및 GPT-3.5와의 비교
160
160
161
-
표 3에서는 Mixtral 8x7B를 Llama 2 70B 및 GPT-3.5와 비교한 성능을 보고합니다. Mixtral이 두 모델과 비슷하거나 더 나은 성능을 보이는 것을 관찰할 수 있습니다. MMLU에서 Mixtral은 상당히 작은 용량(70B에 비해 47B 토큰)에도 불구하고 더 나은 성능을 얻었습니다. MT Bench의 경우, 가장 최신 GPT-3.5-Turbo 모델인 gpt-3.5-turbo-1106의 성능을 보고합니다.
161
+
아래 표에서는 Mixtral 8x7B를 Llama 2 70B 및 GPT-3.5와 비교한 성능을 보고합니다. Mixtral이 두 모델과 비슷하거나 더 나은 성능을 보이는 것을 관찰할 수 있습니다. MMLU에서 Mixtral은 상당히 작은 용량(70B에 비해 47B 토큰)에도 불구하고 더 나은 성능을 얻었습니다. MT Bench의 경우, 가장 최신 GPT-3.5-Turbo 모델인 gpt-3.5-turbo-1106의 성능을 보고합니다.
162
162
163
163
|| LLaMA 2 70B | GPT-3.5 | Mixtral 8x7B |
164
164
|---|---|---|---|
@@ -207,15 +207,15 @@ Mixtral의 다국어 성능 향상은 사전 학습 과정에서 다국어 데
207
207
208
208
Mixtral 모델의 장거리 컨텍스트 처리 능력을 평가하기 위해, [Beltagy와 연구진](https://arxiv.org/pdf/2305.16300)이 소개한 패스키 검색 작업(passkey retrieval task)을 활용했습니다. 이 작업은 긴 프롬프트 내에 무작위로 삽입된 패스키를 모델이 검색할 수 있는 능력을 측정하기 위해 설계된 합성 작업입니다. 아래 그림(왼쪽)의 결과는 Mixtral이 컨텍스트 길이나 패스키의 위치에 관계없이 100%의 검색 정확도를 달성함을 보여줍니다. 이는 모델이 긴 시퀀스에서도 중요한 정보를 효과적으로 추출할 수 있는 강력한 능력을 갖추고 있음을 의미합니다.
209
209
210
-
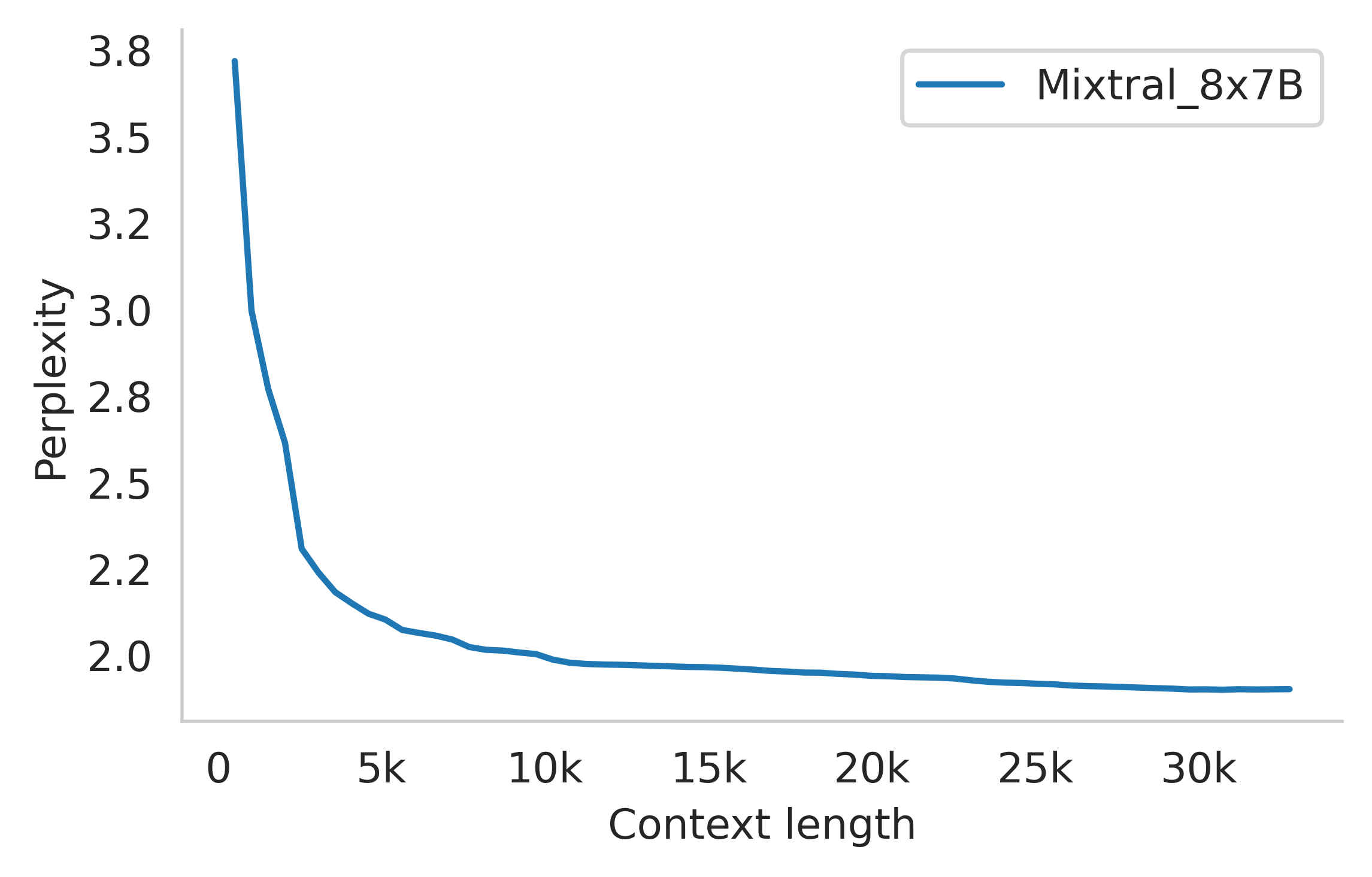
또한 아래 그림(오른쪽)는[Gao와 연구진](https://arxiv.org/pdf/2101.00027)이 개발한 proof-pile 데이터셋의 일부에 대한 Mixtral의 퍼플렉시티(perplexity)가 컨텍스트 크기가 증가함에 따라 단조롭게 감소함을 보여줍니다. 퍼플렉시티는 언어 모델의 성능을 평가하는 지표로, 값이 낮을수록 모델이 텍스트를 더 정확하게 예측한다는 것을 의미합니다. 이 결과는 Mixtral이 더 많은 컨텍스트를 활용할수록 더 정확한 예측을 할 수 있음을 보여주는 중요한 지표입니다.
210
+
또한 아래 그림(오른쪽)은[Gao와 연구진](https://arxiv.org/pdf/2101.00027)이 개발한 proof-pile 데이터셋의 일부에 대한 Mixtral의 퍼플렉시티(perplexity)가 컨텍스트 크기가 증가함에 따라 단조롭게 감소함을 보여줍니다. 퍼플렉시티는 언어 모델의 성능을 평가하는 지표로, 값이 낮을수록 모델이 텍스트를 더 정확하게 예측한다는 것을 의미합니다. 이 결과는 Mixtral이 더 많은 컨텍스트를 활용할수록 더 정확한 예측을 할 수 있음을 보여주는 중요한 지표입니다.
211
211
212
-

212
+
213
213
214
214
### 편향성 벤치마크
215
215
216
-
미세 조정/선호도 모델링을 통해 수정해야 할 잠재적인 결함을 식별하기 위해, 기본 모델의 성능을 Bias Benchmark for QA(BBQ)와 Bias in Open-Ended Language Generation Dataset(BOLD)에서 측정했습니다. BBQ는 [Parrish와 연구진](https://arxiv.org/pdf/2110.08193)이 개발한 데이터셋으로, 연령, 장애 상태, 성 정체성, 국적, 외모, 인종/민족, 종교, 사회경제적 지위, 성적 지향과 같은 9가지 사회적으로 관련된 범주에 대한 사회적 편향을 대상으로 하는 수작업으로 작성된 질문 세트로 구성되어 있습니다. BOLD는 [Dhamala와 연구진](https://arxiv.org/abs/2010.02650)이 개발한 편향성 벤치마킹을 위한 5개 도메인에 걸친 23,679개의 영어 텍스트 생성 프롬프트로 구성된 대규모 데이터셋입니다.
216
+
미세 조정/선호도 모델링을 통해 수정해야 할 잠재적인 결함을 식별하기 위해, 기본 모델의 성능을 Bias Benchmark for QA(BBQ)와 Bias in Open-Ended Language Generation Dataset(BOLD)에서 측정했습니다. BBQ는 [Parrish와 연구진](https://arxiv.org/pdf/2110.08193)이 개발한 데이터셋으로, 연령, 장애 상태, 성 정체성, 국적, 외모, 인종/민족, 종교, 사회경제적 지위, 성적 지향과 같은 9가지 사회적으로 관련된 범주에 대한 사회적 편향을 대상으로 하는 수작업으로 작성된 질문 세트로 구성되어 있습니다. BOLD는 Dhamala와 연구진이 개발한 편향성 벤치마킹을 위한 5개 도메인에 걸친 23,679개의 영어 텍스트 생성 프롬프트로 구성된 대규모 데이터셋입니다.
217
217
218
-
연구팀은 평가 프레임워크를 사용하여 Llama 2와 Mixtral을 BBQ 및 BOLD에서 벤치마킹하고 그 결과를 그림 5에 보고했습니다. Llama 2와 비교했을 때, Mixtral은 BBQ 벤치마크에서 더 적은 편향성을 보였습니다(56.0% 대 51.5%). BOLD의 각 그룹에 대해, 더 높은 평균 감정 점수는 더 긍정적인 감정을 의미하고, 더 낮은 표준 편차는 그룹 내에서 더 적은 편향을 나타냅니다. 전반적으로, Mixtral은 Llama 2보다 더 긍정적인 감정을 표현하며, 각 그룹 내에서 비슷한 변동성을 보입니다.
218
+
연구팀은 평가 프레임워크를 사용하여 Llama 2와 Mixtral을 BBQ 및 BOLD에서 벤치마킹하고 그 결과를 아래와 같이 보고했습니다. Llama 2와 비교했을 때, Mixtral은 BBQ 벤치마크에서 더 적은 편향성을 보였습니다(56.0% 대 51.5%). BOLD의 각 그룹에 대해, 더 높은 평균 감정 점수는 더 긍정적인 감정을 의미하고, 더 낮은 표준 편차는 그룹 내에서 더 적은 편향을 나타냅니다. 전반적으로, Mixtral은 Llama 2보다 더 긍정적인 감정을 표현하며, 각 그룹 내에서 비슷한 변동성을 보입니다.
219
219
220
220
|| Llama 2 70B | Mixtral 8x7B |
221
221
|---|---|---|
@@ -251,8 +251,6 @@ DPO는 [Rafailov와 연구진](https://arxiv.org/pdf/2305.18290)이 제안한
251
251
252
252
이러한 훈련 과정을 통해 개발된 Mixtral-Instruct는 MT-Bench에서 8.30점을 기록했습니다. MT-Bench는 [Zheng과 연구진](https://arxiv.org/pdf/2306.05685)이 개발한 벤치마크로, 대화형 AI 모델의 성능을 평가하기 위한 다양한 카테고리의 다중 턴 질문으로 구성되어 있습니다. 이 점수는 2023년 12월 기준으로 공개 가중치 모델 중 가장 높은 성적입니다.
253
253
254
-
LMSys에서 독립적으로 수행한 인간 평가 결과는 그림 6에 보고되어 있습니다. 이 평가에 따르면 Mixtral-Instruct는 GPT-3.5-Turbo, Gemini Pro, Claude-2.1, Llama 2 70B 채팅 모델을 능가하는 성능을 보여주었습니다.
255
-
256
254

257
255
258
256
위 그림은 LMSys 리더보드의 스크린샷으로, 2023년 12월 22일 기준 Mixtral 8x7B Instruct v0.1의 성능을 보여줍니다. 이 모델은 Arena Elo 평점 1121을 기록하여 Claude-2.1(1117), 모든 버전의 GPT-3.5-Turbo(최고 점수 1117), Gemini Pro(1111), 그리고 Llama-2-70b-chat(1077)을 모두 능가했습니다. 이는 Mixtral이 현재 공개된 가중치 모델 중에서 상당한 차이로 가장 우수한 성능을 보여준다는 것을 의미합니다.
@@ -271,13 +269,13 @@ MT-Bench에서의 높은 점수와 LMSys 평가에서의 우수한 성능은 Mix
271
269
272
270
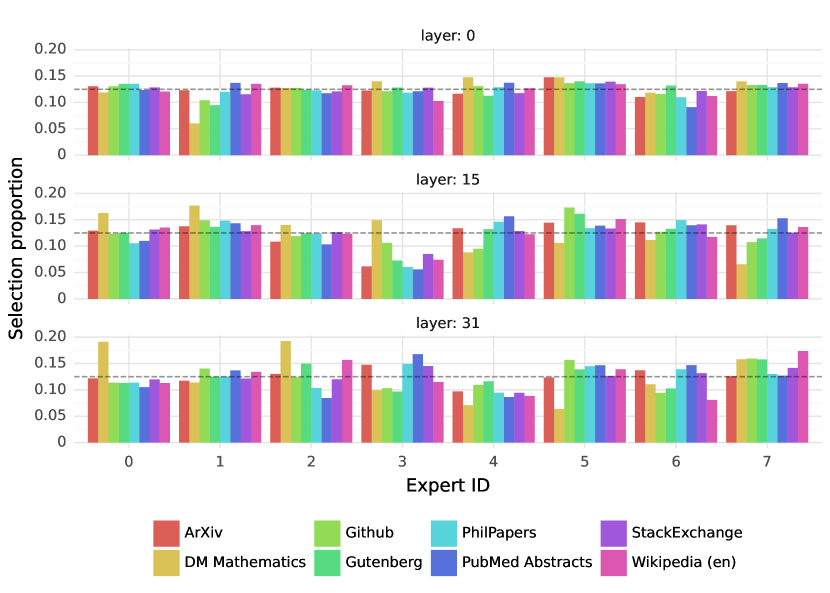
놀랍게도, 주제에 기반한 전문가 할당에서 명확한 패턴은 관찰되지 않았습니다. 예를 들어, 모든 층에서 LaTeX로 작성된 ArXiv 논문, 생물학(PubMed Abstracts), 철학(PhilPapers) 문서에 대한 전문가 할당 분포는 매우 유사했습니다. 오직 DM Mathematics에서만 약간 다른 전문가 분포가 관찰되었습니다. 이러한 차이는 데이터셋의 합성적 특성과 자연어 스펙트럼의 제한된 범위 때문일 가능성이 높으며, 특히 입력 및 출력 임베딩과 매우 상관관계가 높은 첫 번째 층과 마지막 층에서 두드러집니다. 이는 라우터가 일종의 구조화된 구문적 행동을 보여준다는 것을 시사합니다.
273
271
274
-

272
+
275
273
276
274
아래 그림은 다양한 도메인(Python 코드, 수학, 영어)의 텍스트 예시를 보여주며, 각 토큰은 선택된 전문가에 해당하는 배경색으로 강조되어 있습니다. 이 그림은 Python의 'self'와 영어의 'Question'과 같은 단어들이 여러 토큰으로 구성되어 있음에도 불구하고 종종 동일한 전문가를 통해 라우팅된다는 것을 보여줍니다. 마찬가지로 코드에서 들여쓰기 토큰은 항상 동일한 전문가에 할당되는데, 특히 은닉 상태가 모델의 입력 및 출력과 더 상관관계가 높은 첫 번째 및 마지막 층에서 그러합니다.
277
275
278
276
또한 아래 그림에서 연속된 토큰들이 종종 동일한 전문가에 할당되는 것을 관찰할 수 있습니다. 실제로 The Pile 데이터셋에서 일정 수준의 위치적 지역성(positional locality)이 관찰됩니다.
279
277
280
-

278
+

0 commit comments