|
| 1 | +# AWS Lambda Response streaming: Streaming incremental Amazon DynamoDB Query results. |
| 2 | + |
| 3 | +This pattern shows how to use Lambda response streaming to incrementally retrieve and stream DynamoDB query / scan results using the write() method. Instead of waiting for the entire query / scan operation to complete, the Lambda function streams data in batches by setting a limit on the number of items per query and sending each batch as soon as it's retrieved. This improves the time-to-first-byte (TTFB) by streaming results to the client as they become available. |
| 4 | + |
| 5 | +For more information on the Lambda response streaming feature, see the [launch blog post](https://aws.amazon.com/blogs/compute/introducing-aws-lambda-response-streaming/). |
| 6 | + |
| 7 | +Important: this application uses various AWS services and there are costs associated with these services after the Free Tier usage - please see the [AWS Pricing page](https://aws.amazon.com/pricing/) for details. You are responsible for any AWS costs incurred. No warranty is implied in this example. |
| 8 | + |
| 9 | +## Requirements |
| 10 | + |
| 11 | +- [Create an AWS account](https://portal.aws.amazon.com/gp/aws/developer/registration/index.html) if you do not already have one and log in. The IAM user that you use must have sufficient permissions to make necessary AWS service calls and manage AWS resources. |
| 12 | +- [AWS CLI](https://docs.aws.amazon.com/cli/latest/userguide/install-cliv2.html) installed and configured |
| 13 | +- [Git Installed](https://git-scm.com/book/en/v2/Getting-Started-Installing-Git) |
| 14 | +- [AWS Serverless Application Model](https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/serverless-sam-cli-install.html) (AWS SAM) installed |
| 15 | + |
| 16 | +## Deployment Instructions |
| 17 | + |
| 18 | +1. Create a new directory, navigate to that directory in a terminal and clone the GitHub repository: |
| 19 | + |
| 20 | +``` |
| 21 | +git clone https://github.com/aws-samples/serverless-patterns |
| 22 | +``` |
| 23 | + |
| 24 | +1. Change directory to the pattern directory: |
| 25 | + |
| 26 | + ``` |
| 27 | + cd lambda-streaming-ttfb-write-sam-with-dynamodb |
| 28 | + ``` |
| 29 | + |
| 30 | +1. From the command line, use AWS SAM to deploy the AWS resources for the pattern as specified in the template.yml file: |
| 31 | + |
| 32 | + ``` |
| 33 | + sam deploy -g --stack-name lambda-streaming-ttfb-write-sam-with-dynamodb |
| 34 | + ``` |
| 35 | + |
| 36 | +1. During the prompts: |
| 37 | + |
| 38 | + - Enter a stack name |
| 39 | + - Enter the desired AWS Region |
| 40 | + - Allow SAM CLI to create IAM roles with the required permissions. |
| 41 | + |
| 42 | +1. After running `sam deploy --guided` mode once and saving arguments to a configuration file `samconfig.toml`, you can use `sam deploy` in future to use these defaults. |
| 43 | + |
| 44 | +AWS SAM deploys a Lambda function with streaming support and a function URL |
| 45 | + |
| 46 | + |
| 47 | + |
| 48 | +The AWS SAM output returns a Lambda function URL. |
| 49 | + |
| 50 | +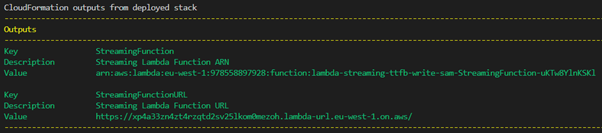 |
| 51 | + |
| 52 | +## How it works |
| 53 | + |
| 54 | +The service interaction in this pattern uses AWS Lambda's response streaming capability to stream data in batches from Amazon DynamoDB. Instead of retrieving all query / scan results at once, the Lambda function processes the query incrementally, retrieving and sending results as they become available. Here are the details of the interaction: |
| 55 | + |
| 56 | +1. Client Request |
| 57 | + A client sends a request to the Lambda URL, asking for specific data from a DynamoDB table. |
| 58 | +2. Lambda Function Initialization : |
| 59 | + When the Lambda function is invoked, it initializes a connection to DynamoDB and prepares to run a query operation. The query includes a limit parameter, which restricts the number of items retrieved in each batch. |
| 60 | +3. Querying |
| 61 | + The Lambda function begins querying DynamoDB using the defined limit (e.g., 100 items per batch). DynamoDB will return only a limited set of results instead of the entire result set at once. |
| 62 | +4. Response Streaming |
| 63 | + As soon as a batch of results is retrieved, the function uses Lambda's streaming API `write()` method to send the data to the client. This happens immediately, without waiting for the entire query operation to complete. |
| 64 | +5. Pagination Handling |
| 65 | + If DynamoDB returns a LastEvaluatedKey (which indicates that more data is available), the Lambda function automatically continues querying the next batch of data. Each batch is streamed to the client as it becomes available. |
| 66 | +6. Final Response |
| 67 | + The Lambda function continues this process, retrieving a batch from DynamoDB and streaming it to the client until all data is fetched. Once DynamoDB returns no more data (i.e., no LastEvaluatedKey), the function sends the final batch and closes the stream. |
| 68 | + |
| 69 | +## Testing |
| 70 | + |
| 71 | +1. Run the data dump function to populate the DynamoDB table. |
| 72 | + |
| 73 | + Use curl with your AWS credentials as the url uses AWS Identity and Access Management (IAM) for authorization. Replace the URL and Region parameters for your deployment. |
| 74 | + |
| 75 | + ``` |
| 76 | + curl --request GET https://<url-of-data-dump-lambda>.lambda-url.<Region>.on.aws/ --user AKIAIOSFODNN7EXAMPLE:wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY --aws-sigv4 'aws:amz:<Region>:lambda' |
| 77 | + ``` |
| 78 | + |
| 79 | +2. Run the streaming function to view the streaming response. |
| 80 | + |
| 81 | + Use curl with your AWS credentials to view the streaming response as the url uses AWS Identity and Access Management (IAM) for authorization. Replace the URL and Region parameters for your deployment. |
| 82 | + |
| 83 | + ``` |
| 84 | + curl --request GET https://<url-of-streaming-lambda>.lambda-url.<Region>.on.aws/ --user AKIAIOSFODNN7EXAMPLE:wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY --aws-sigv4 'aws:amz:<Region>:lambda' |
| 85 | + ``` |
| 86 | + |
| 87 | + You can see the gradual display of the streamed response. |
| 88 | + |
| 89 | +## Cleanup |
| 90 | + |
| 91 | +1. Delete the stack, Enter `Y` to confirm deleting the stack and folder. |
| 92 | + ``` |
| 93 | + sam delete |
| 94 | + ``` |
| 95 | + |
| 96 | +--- |
| 97 | + |
| 98 | +Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved. |
| 99 | + |
| 100 | +SPDX-License-Identifier: MIT-0 |
0 commit comments