|
| 1 | +## Redis 集群模式的工作原理 |
| 2 | + |
| 3 | +Redis 集群模式的工作原理?在集群模式下,Redis 的 key 是如何寻址的?分布式寻址都有哪些算法?了解一致性 hash 算法吗? |
| 4 | + |
| 5 | +在前几年,Redis 如果要搞几个节点,每个节点存储一部分的数据,得**借助一些中间件**来实现,比如说有 `codis` ,或者 `twemproxy` ,都有。有一些 Redis 中间件,你读写 Redis 中间件,Redis 中间件负责将你的数据分布式存储在多台机器上的 Redis 实例中。 |
| 6 | + |
| 7 | +这两年,Redis 不断在发展,Redis 也不断有新的版本,现在的 Redis 集群模式,可以做到在多台机器上,部署多个 Redis 实例,每个实例存储一部分的数据,同时每个 Redis 主实例可以挂 Redis 从实例,自动确保说,如果 Redis 主实例挂了,会自动切换到 Redis 从实例上来。 |
| 8 | + |
| 9 | +现在 Redis 的新版本,大家都是用 Redis cluster 的,也就是 Redis 原生支持的 Redis 集群模式,那么面试官肯定会就 Redis cluster 对你来个几连炮。要是你没用过 Redis cluster,正常,以前很多人用 codis 之类的客户端来支持集群,但是起码你得研究一下 Redis cluster 吧。 |
| 10 | + |
| 11 | +如果你的数据量很少,主要是承载高并发高性能的场景,比如你的缓存一般就几个 G,单机就足够了,可以使用 replication,一个 master 多个 slaves,要几个 slave 跟你要求的读吞吐量有关,然后自己搭建一个 sentinel 集群去保证 Redis 主从架构的高可用性。 |
| 12 | + |
| 13 | +Redis cluster,主要是针对**海量数据+高并发+高可用**的场景。Redis cluster 支撑 N 个 Redis master node,每个 master node 都可以挂载多个 slave node。这样整个 Redis 就可以横向扩容了。如果你要支撑更大数据量的缓存,那就横向扩容更多的 master 节点,每个 master 节点就能存放更多的数据了。 |
| 14 | + |
| 15 | +### Redis cluster 介绍 |
| 16 | + |
| 17 | +- 自动将数据进行分片,每个 master 上放一部分数据 |
| 18 | +- 提供内置的高可用支持,部分 master 不可用时,还是可以继续工作的 |
| 19 | + |
| 20 | +在 Redis cluster 架构下,每个 Redis 要放开两个端口号,比如一个是 6379,另外一个就是 加 1w 的端口号,比如 16379。 |
| 21 | + |
| 22 | +16379 端口号是用来进行节点间通信的,也就是 cluster bus 的东西,cluster bus 的通信,用来进行故障检测、配置更新、故障转移授权。cluster bus 用了另外一种二进制的协议, `gossip` 协议,用于节点间进行高效的数据交换,占用更少的网络带宽和处理时间。 |
| 23 | + |
| 24 | +### 节点间的内部通信机制 |
| 25 | + |
| 26 | +#### 基本通信原理 |
| 27 | + |
| 28 | +集群元数据的维护有两种方式:集中式、Gossip 协议。Redis cluster 节点间采用 gossip 协议进行通信。 |
| 29 | + |
| 30 | +**集中式**是将集群元数据(节点信息、故障等等)集中存储在某个节点上。集中式元数据集中存储的一个典型代表,就是大数据领域的 `storm` 。它是分布式的大数据实时计算引擎,是集中式的元数据存储的结构,底层基于 zookeeper(分布式协调的中间件)对所有元数据进行存储维护。 |
| 31 | + |
| 32 | +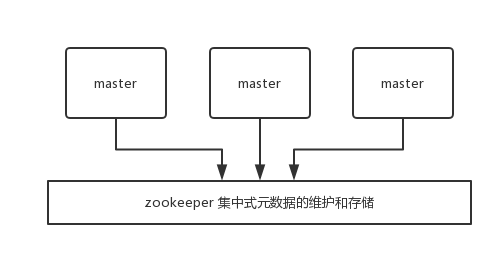 |
| 33 | + |
| 34 | +Redis 维护集群元数据采用另一个方式, `gossip` 协议,所有节点都持有一份元数据,不同的节点如果出现了元数据的变更,就不断将元数据发送给其它的节点,让其它节点也进行元数据的变更。 |
| 35 | + |
| 36 | + |
| 37 | + |
| 38 | +**集中式**的**好处**在于,元数据的读取和更新,时效性非常好,一旦元数据出现了变更,就立即更新到集中式的存储中,其它节点读取的时候就可以感知到;**不好**在于,所有的元数据的更新压力全部集中在一个地方,可能会导致元数据的存储有压力。 |
| 39 | + |
| 40 | +gossip 好处在于,元数据的更新比较分散,不是集中在一个地方,更新请求会陆陆续续打到所有节点上去更新,降低了压力;不好在于,元数据的更新有延时,可能导致集群中的一些操作会有一些滞后。 |
| 41 | + |
| 42 | +- 10000 端口:每个节点都有一个专门用于节点间通信的端口,就是自己提供服务的端口号+10000,比如 7001,那么用于节点间通信的就是 17001 端口。每个节点每隔一段时间都会往另外几个节点发送 `ping` 消息,同时其它几个节点接收到 `ping` 之后返回 `pong` 。 |
| 43 | +- 交换的信息:信息包括故障信息,节点的增加和删除,hash slot 信息等等。 |
| 44 | + |
| 45 | +#### gossip 协议 |
| 46 | + |
| 47 | +gossip 协议包含多种消息,包含 `ping` , `pong` , `meet` , `fail` 等等。 |
| 48 | + |
| 49 | +- meet:某个节点发送 meet 给新加入的节点,让新节点加入集群中,然后新节点就会开始与其它节点进行通信。 |
| 50 | + |
| 51 | +```bash |
| 52 | +Redis-trib.rb add-nodeCopy to clipboardErrorCopied |
| 53 | +``` |
| 54 | + |
| 55 | +其实内部就是发送了一个 gossip meet 消息给新加入的节点,通知那个节点去加入我们的集群。 |
| 56 | + |
| 57 | +- ping:每个节点都会频繁给其它节点发送 ping,其中包含自己的状态还有自己维护的集群元数据,互相通过 ping 交换元数据。 |
| 58 | +- pong:返回 ping 和 meet,包含自己的状态和其它信息,也用于信息广播和更新。 |
| 59 | +- fail:某个节点判断另一个节点 fail 之后,就发送 fail 给其它节点,通知其它节点说,某个节点宕机啦。 |
| 60 | + |
| 61 | +#### ping 消息深入 |
| 62 | + |
| 63 | +ping 时要携带一些元数据,如果很频繁,可能会加重网络负担。 |
| 64 | + |
| 65 | +每个节点每秒会执行 10 次 ping,每次会选择 5 个最久没有通信的其它节点。当然如果发现某个节点通信延时达到了 `cluster_node_timeout / 2` ,那么立即发送 ping,避免数据交换延时过长,落后的时间太长了。比如说,两个节点之间都 10 分钟没有交换数据了,那么整个集群处于严重的元数据不一致的情况,就会有问题。所以 `cluster_node_timeout` 可以调节,如果调得比较大,那么会降低 ping 的频率。 |
| 66 | + |
| 67 | +每次 ping,会带上自己节点的信息,还有就是带上 1/10 其它节点的信息,发送出去,进行交换。至少包含 `3` 个其它节点的信息,最多包含 `总节点数减 2` 个其它节点的信息。 |
| 68 | + |
| 69 | +### 分布式寻址算法 |
| 70 | + |
| 71 | +- hash 算法(大量缓存重建) |
| 72 | +- 一致性 hash 算法(自动缓存迁移)+ 虚拟节点(自动负载均衡) |
| 73 | +- Redis cluster 的 hash slot 算法 |
| 74 | + |
| 75 | +#### hash 算法 |
| 76 | + |
| 77 | +来了一个 key,首先计算 hash 值,然后对节点数取模。然后打在不同的 master 节点上。一旦某一个 master 节点宕机,所有请求过来,都会基于最新的剩余 master 节点数去取模,尝试去取数据。这会导致**大部分的请求过来,全部无法拿到有效的缓存**,导致大量的流量涌入数据库。 |
| 78 | + |
| 79 | +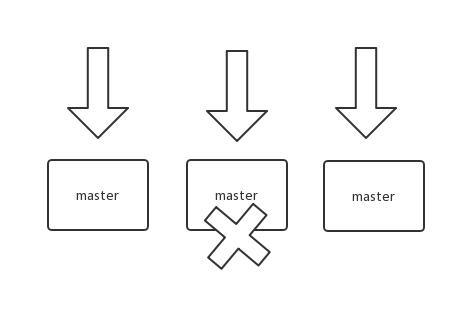 |
| 80 | + |
| 81 | +#### 一致性 hash 算法 |
| 82 | + |
| 83 | +一致性 hash 算法将整个 hash 值空间组织成一个虚拟的圆环,整个空间按顺时针方向组织,下一步将各个 master 节点(使用服务器的 ip 或主机名)进行 hash。这样就能确定每个节点在其哈希环上的位置。 |
| 84 | + |
| 85 | +来了一个 key,首先计算 hash 值,并确定此数据在环上的位置,从此位置沿环**顺时针“行走”**,遇到的第一个 master 节点就是 key 所在位置。 |
| 86 | + |
| 87 | +在一致性哈希算法中,如果一个节点挂了,受影响的数据仅仅是此节点到环空间前一个节点(沿着逆时针方向行走遇到的第一个节点)之间的数据,其它不受影响。增加一个节点也同理。 |
| 88 | + |
| 89 | +燃鹅,一致性哈希算法在节点太少时,容易因为节点分布不均匀而造成**缓存热点**的问题。为了解决这种热点问题,一致性 hash 算法引入了虚拟节点机制,即对每一个节点计算多个 hash,每个计算结果位置都放置一个虚拟节点。这样就实现了数据的均匀分布,负载均衡。 |
| 90 | + |
| 91 | +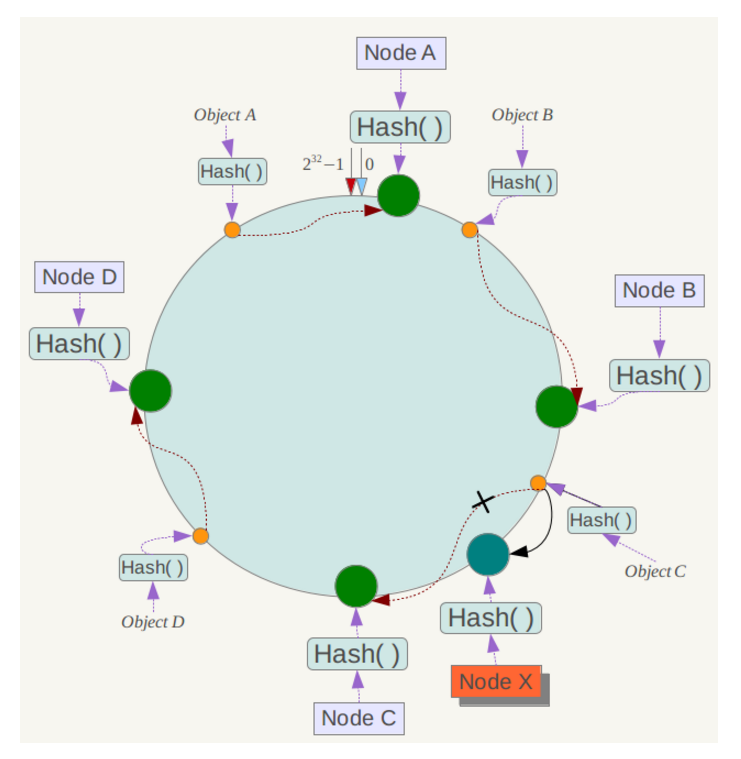 |
| 92 | + |
| 93 | +#### Redis cluster 的 hash slot 算法 |
| 94 | + |
| 95 | +Redis cluster 有固定的 `16384` 个 hash slot,对每个 `key` 计算 `CRC16` 值,然后对 `16384` 取模,可以获取 key 对应的 hash slot。 |
| 96 | + |
| 97 | +Redis cluster 中每个 master 都会持有部分 slot,比如有 3 个 master,那么可能每个 master 持有 5000 多个 hash slot。hash slot 让 node 的增加和移除很简单,增加一个 master,就将其他 master 的 hash slot 移动部分过去,减少一个 master,就将它的 hash slot 移动到其他 master 上去。移动 hash slot 的成本是非常低的。客户端的 api,可以对指定的数据,让他们走同一个 hash slot,通过 `hash tag` 来实现。 |
| 98 | + |
| 99 | +任何一台机器宕机,另外两个节点,不影响的。因为 key 找的是 hash slot,不是机器。 |
| 100 | + |
| 101 | +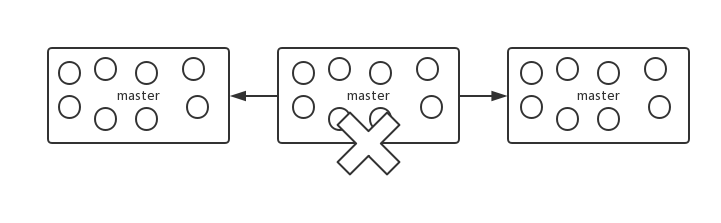 |
| 102 | + |
| 103 | +### Redis cluster 的高可用与主备切换原理 |
| 104 | + |
| 105 | +Redis cluster 的高可用的原理,几乎跟哨兵是类似的。 |
| 106 | + |
| 107 | +#### 判断节点宕机 |
| 108 | + |
| 109 | +如果一个节点认为另外一个节点宕机,那么就是 `pfail` ,**主观宕机**。如果多个节点都认为另外一个节点宕机了,那么就是 `fail` ,**客观宕机**,跟哨兵的原理几乎一样,sdown,odown。 |
| 110 | + |
| 111 | +在 `cluster-node-timeout` 内,某个节点一直没有返回 `pong` ,那么就被认为 `pfail` 。 |
| 112 | + |
| 113 | +如果一个节点认为某个节点 `pfail` 了,那么会在 `gossip ping` 消息中, `ping` 给其他节点,如果**超过半数**的节点都认为 `pfail` 了,那么就会变成 `fail` 。 |
| 114 | + |
| 115 | +#### 从节点过滤 |
| 116 | + |
| 117 | +对宕机的 master node,从其所有的 slave node 中,选择一个切换成 master node。 |
| 118 | + |
| 119 | +检查每个 slave node 与 master node 断开连接的时间,如果超过了 `cluster-node-timeout * cluster-slave-validity-factor` ,那么就**没有资格**切换成 `master` 。 |
| 120 | + |
| 121 | +#### 从节点选举 |
| 122 | + |
| 123 | +每个从节点,都根据自己对 master 复制数据的 offset,来设置一个选举时间,offset 越大(复制数据越多)的从节点,选举时间越靠前,优先进行选举。 |
| 124 | + |
| 125 | +所有的 master node 开始 slave 选举投票,给要进行选举的 slave 进行投票,如果大部分 master node `(N/2 + 1)` 都投票给了某个从节点,那么选举通过,那个从节点可以切换成 master。 |
| 126 | + |
| 127 | +从节点执行主备切换,从节点切换为主节点。 |
| 128 | + |
| 129 | +#### 与哨兵比较 |
| 130 | + |
| 131 | +整个流程跟哨兵相比,非常类似,所以说,Redis cluster 功能强大,直接集成了 replication 和 sentinel 的功能。 |
| 132 | + |
| 133 | + |
| 134 | + |
| 135 | +> 参考链接:https://doocs.github.io/advanced-java/#/docs/high-concurrency/redis-cluster |
0 commit comments