|
95 | 95 |
|
96 | 96 | 黑白双方负责接受用户的输入,并告知棋盘系统棋子布局发生变化,棋盘系统接收到了棋子的变化的信息就负责在屏幕上面显示出这种变化,同时利用规则系统来对棋局进行判定。 |
97 | 97 |
|
98 | | -## JKD和JRE的区别? |
| 98 | +## JKD/JRE/JVM三者的关系 |
99 | 99 |
|
100 | | -JDK和JRE是Java开发和运行工具,其中JDK包含了JRE,而JRE是可以独立安装的。 |
| 100 | +### JVM |
101 | 101 |
|
102 | | -**JDK**:Java Development Kit,JAVA语言的软件工具开发包,是整个JAVA开发的核心,它包含了JAVA的运行(JVM+JAVA类库)环境和JAVA工具。 |
| 102 | +**JVM** :英文名称(Java Virtual Machine),就是我们耳熟能详的 Java 虚拟机。Java 能够跨平台运行的核心在于 JVM 。 |
103 | 103 |
|
104 | | -**JRE**:Java Runtime Environment,Java运行环境,包含JVM标准实现及Java核心类库。JRE是Java运行环境,并不是一个开发环境,所以没有包含任何开发工具(如编译器和调试器)。 |
| 104 | +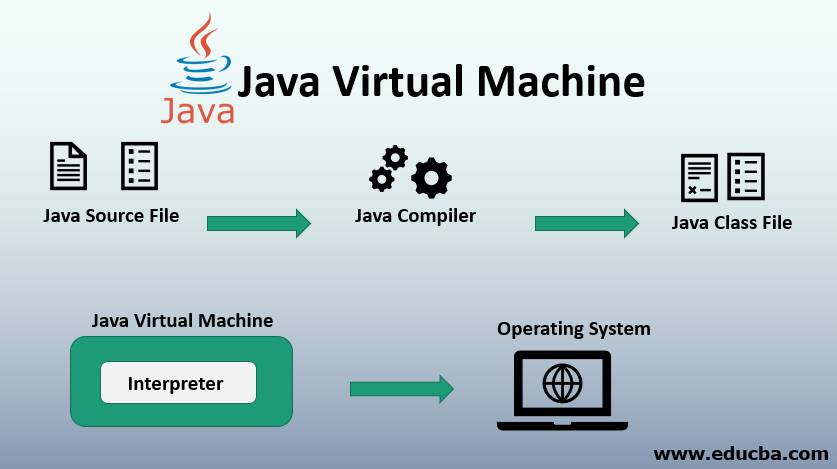 |
105 | 105 |
|
106 | | -JRE是运行基于Java语言编写的程序所不可缺少的运行环境。也是通过它,Java的开发者才得以将自己开发的程序发布到用户手中,让用户使用。 |
| 106 | +所有的java程序会首先被编译为.class的类文件,这种类文件可以在虚拟机上执行。也就是说class文件并不直接与机器的操作系统交互,而是经过虚拟机间接与操作系统交互,由虚拟机将程序解释给本地系统执行。 |
| 107 | + |
| 108 | +针对不同的系统有不同的 jvm 实现,有 Linux 版本的 jvm 实现,也有Windows 版本的 jvm 实现,但是同一段代码在编译后的字节码是一样的。这就是Java能够跨平台,实现一次编写,多处运行的原因所在。 |
| 109 | + |
| 110 | +### JRE |
| 111 | + |
| 112 | +英文名称(Java Runtime Environment),就是Java 运行时环境。我们编写的Java程序必须要在JRE才能运行。它主要包含两个部分,JVM 和 Java 核心类库。 |
| 113 | + |
| 114 | +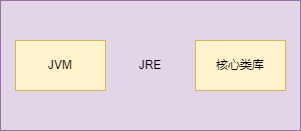 |
| 115 | + |
| 116 | +JRE是Java的运行环境,并不是一个开发环境,所以没有包含任何开发工具,如编译器和调试器等。 |
| 117 | + |
| 118 | +如果你只是想运行Java程序,而不是开发Java程序的话,那么你只需要安装JRE即可。 |
| 119 | + |
| 120 | +### JDK |
| 121 | + |
| 122 | +英文名称(Java Development Kit),就是 Java 开发工具包 |
| 123 | + |
| 124 | +学过Java的同学,都应该安装过JDK。当我们安装完JDK之后,目录结构是这样的 |
| 125 | + |
| 126 | +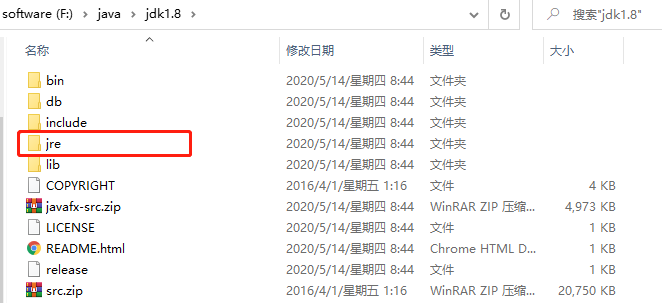 |
| 127 | + |
| 128 | +可以看到,JDK目录下有个JRE,也就是JDK中已经集成了 JRE,不用单独安装JRE。 |
| 129 | + |
| 130 | +另外,JDK中还有一些好用的工具,如jinfo,jps,jstack等。 |
| 131 | + |
| 132 | + |
| 133 | + |
| 134 | + |
| 135 | + |
| 136 | +### 总结 |
| 137 | + |
| 138 | +最后,总结一下JDK/JRE/JVM,他们三者的关系 |
| 139 | + |
| 140 | +JRE = JVM + Java 核心类库 |
| 141 | + |
| 142 | +JDK = JRE + Java工具 + 编译器 + 调试器 |
| 143 | + |
| 144 | +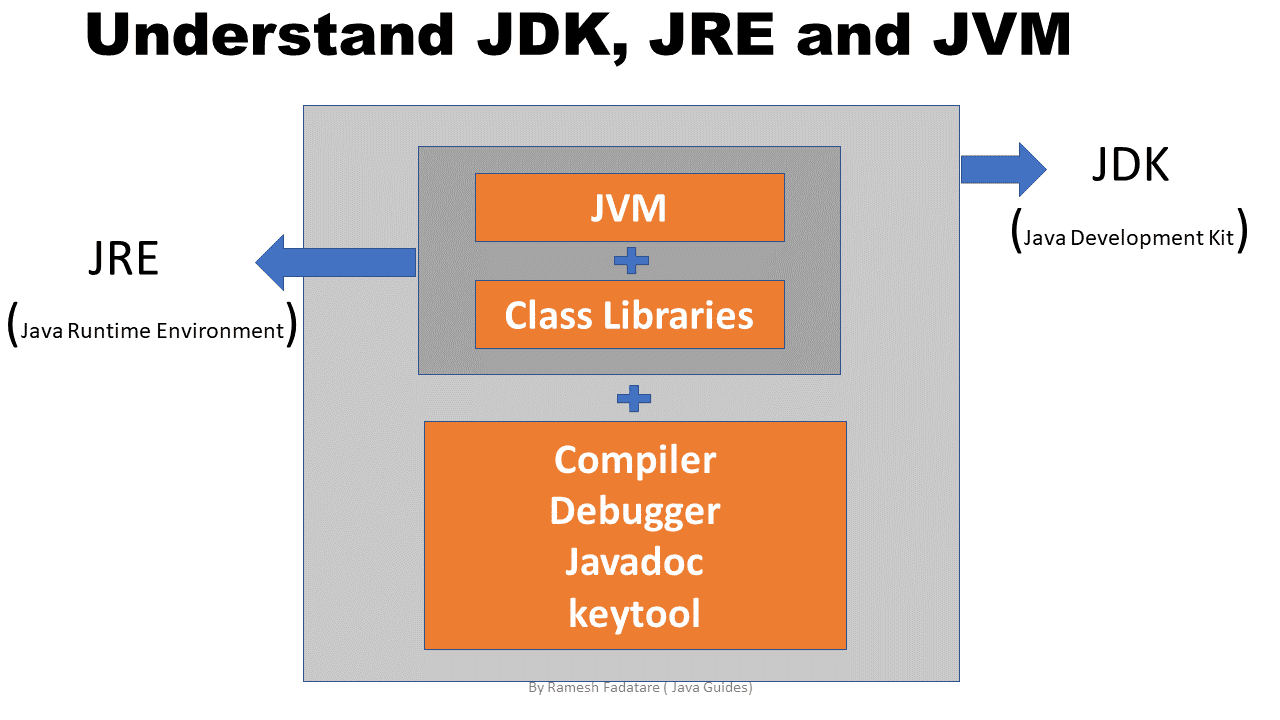 |
107 | 145 |
|
108 | 146 | ## 面向对象有哪些特性? |
109 | 147 |
|
@@ -944,6 +982,76 @@ unchecked Exception: |
944 | 982 |
|
945 | 983 | - **throws**:用在方法签名中,用于声明该方法可能抛出的异常。子类方法抛出的异常范围更加小,或者根本不抛异常。 |
946 | 984 |
|
| 985 | +## 通过故事讲清楚NIO |
| 986 | + |
| 987 | +下面通过一个例子来讲解下。 |
| 988 | + |
| 989 | +假设某银行只有10个职员。该银行的业务流程分为以下4个步骤: |
| 990 | + |
| 991 | +1) 顾客填申请表(5分钟); |
| 992 | + |
| 993 | +2) 职员审核(1分钟); |
| 994 | + |
| 995 | +3) 职员叫保安去金库取钱(3分钟); |
| 996 | + |
| 997 | +4) 职员打印票据,并将钱和票据返回给顾客(1分钟)。 |
| 998 | + |
| 999 | +下面我们看看银行不同的工作方式对其工作效率到底有何影响。 |
| 1000 | + |
| 1001 | +首先是BIO方式。 |
| 1002 | + |
| 1003 | +每来一个顾客,马上由一位职员来接待处理,并且这个职员需要负责以上4个完整流程。当超过10个顾客时,剩余的顾客需要排队等候。 |
| 1004 | + |
| 1005 | +一个职员处理一个顾客需要10分钟(5+1+3+1)时间。一个小时(60分钟)能处理6个顾客,一共10个职员,那就是只能处理60个顾客。 |
| 1006 | + |
| 1007 | +可以看到银行职员的工作状态并不饱和,比如在第1步,其实是处于等待中。 |
| 1008 | + |
| 1009 | +这种工作其实就是BIO,每次来一个请求(顾客),就分配到线程池中由一个线程(职员)处理,如果超出了线程池的最大上限(10个),就扔到队列等待 。 |
| 1010 | + |
| 1011 | +那么如何提高银行的吞吐量呢? |
| 1012 | + |
| 1013 | +思路就是:**分而治之**,将任务拆分开来,由专门的人负责专门的任务。 |
| 1014 | + |
| 1015 | +具体来讲,银行专门指派一名职员A,A的工作就是每当有顾客到银行,他就递上表格让顾客填写。每当有顾客填好表后,A就将其随机指派给剩余的9名职员完成后续步骤。 |
| 1016 | + |
| 1017 | +这种方式下,假设顾客非常多,职员A的工作处于饱和中,他不断的将填好表的顾客带到柜台处理。 |
| 1018 | + |
| 1019 | +柜台一个职员5分钟能处理完一个顾客,一个小时9名职员能处理:9*(60/5)=108。 |
| 1020 | + |
| 1021 | +可见工作方式的转变能带来效率的极大提升。 |
| 1022 | + |
| 1023 | +这种工作方式其实就NIO的思路。 |
| 1024 | + |
| 1025 | +下图是非常经典的NIO说明图,`mainReactor`线程负责监听server socket,接收新连接,并将建立的socket分派给`subReactor` |
| 1026 | + |
| 1027 | +`subReactor`可以是一个线程,也可以是线程池,负责多路分离已连接的socket,读写网络数据。这里的读写网络数据可类比顾客填表这一耗时动作,对具体的业务处理功能,其扔给worker线程池完成 |
| 1028 | + |
| 1029 | +可以看到典型NIO有三类线程,分别是`mainReactor`线程、`subReactor`线程、`work`线程。 |
| 1030 | + |
| 1031 | +不同的线程干专业的事情,最终每个线程都没空着,系统的吞吐量自然就上去了。 |
| 1032 | + |
| 1033 | + |
| 1034 | + |
| 1035 | + |
| 1036 | + |
| 1037 | +**那这个流程还有没有什么可以提高的地方呢?** |
| 1038 | + |
| 1039 | +可以看到,在这个业务流程里边第3个步骤,职员叫保安去金库取钱(3分钟)。这3分钟柜台职员是在等待中度过的,可以把这3分钟利用起来。 |
| 1040 | + |
| 1041 | +还是分而治之的思路,指派1个职员B来专门负责第3步骤。 |
| 1042 | + |
| 1043 | +每当柜台员工完成第2步时,就通知职员B来负责与保安沟通取钱。这时候柜台员工可以继续处理下一个顾客。 |
| 1044 | + |
| 1045 | +当职员B拿到钱之后,通知顾客钱已经到柜台了,让顾客重新排队处理,当柜台职员再次服务该顾客时,发现该顾客前3步已经完成,直接执行第4步即可。 |
| 1046 | + |
| 1047 | +在当今web服务中,经常需要通过RPC或者Http等方式调用第三方服务,这里对应的就是第3步,如果这步耗时较长,通过异步方式将能极大降低资源使用率。 |
| 1048 | + |
| 1049 | +NIO+异步的方式能让少量的线程做大量的事情。这适用于很多应用场景,比如代理服务、api服务、长连接服务等等。这些应用如果用同步方式将耗费大量机器资源。 |
| 1050 | + |
| 1051 | +不过虽然NIO+异步能提高系统吞吐量,但其并不能让一个请求的等待时间下降,相反可能会增加等待时间。 |
| 1052 | + |
| 1053 | +最后,NIO基本思想总结起来就是:**分而治之,将任务拆分开来,由专门的人负责专门的任务** |
| 1054 | + |
947 | 1055 | ## BIO/NIO/AIO区别的区别? |
948 | 1056 |
|
949 | 1057 | **同步阻塞IO** : 用户进程发起一个IO操作以后,必须等待IO操作的真正完成后,才能继续运行。 |
|
0 commit comments